Binary instrumentation and Frida¶
This section should give you a brief but general understanding of what binary instrumentation is and will be useful even if you use other tools or write your own ones (you are free to first read Section 3. About Frida).
Binary instrumentation consists on injecting instrumentation code which is transparent to the target application so that we can obtain behavioral information during its execution. With Frida during the instrumentation process, not only we have detailed information about the binary structure but also it is possible to modify the execution flow of an application while it is running.
In particular, the instrumentation process allows us to obtain information on:
- The assembly instructions executed by the process.
- Function arguments (whenever functions are called).
- Returned values from called functions.
- Pointer data.
This information is very valuable because it allows us to quickly learn about how functions their data(such as parameters, local variables or return values) are used in the target process. However, from the point of view of a malware analyst, the capacity of altering the course of the execution of an application is perhaps even more useful. The instrumentation process allows modifying the execution flow of the application given certain conditions, as well as modify registers given certain instruction patterns.
There are multiple applications of binary instrumentation:
- Reverse engineering: Allows to quickly obtain information about a binary or process, especially on scenarios where static analysis time is limited. For example during static analysis we can notice certain functions are being called lots of times but we don't have time to check their input manually, this we can automate.
- Malware Analysis: It can be used to obtain a quick behavioral report from a malicious process by inspecting popular APIs, introducing breakpoints or modifying its control flow. It also allows exporting the knowledge we gained from a quick static analysis to check if our findings are correct.
- Fuzzing: Manipulating data throughout the execution of the application so that we can force errors or race conditions in an application, leading to vulnerabilities.
- Taint Analysis: Check all the variables controlled by the user and take advantage of this to examine memory regions and registers to see how they are affected by the user-controlled input.
- Measure performance: It is possible to measure the performance of specific code sections or instruction sets, although this is usually done along with the source code.
Application and code-level instrumentation¶
Depending on the level of access to our target application, two main types of instrumentation can be differentiated:
- Application-level instrumentation: We are able to instrument applications for which we don't have access to its source code, as long as we provide an environment where it can run. Aside from few cases where there are code leaks, most malware binaries do not have their source code available so this method fits perfectly for this use case.
- Code-level instrumentation: Given access to the applications source code, we can instrument and trace certain sections of the code to measure its performance, find bugs or obtain any information that is of interest to either the analyst or the developer.
In addition, application-level instrumentation helps us to speed up static analysis scenarios and is where this type of instrumentation shines. The reason behind this is that it allows us to retrieve information from function arguments, return values, stack and registers without the need to manually reverse engineer the complete binary. There is also the possibility of probing certain blocks of code to monitor how they are being accessed or where they are called from, which is very helpful when tracking down the execution chain of functions.
Frida can be embedded as a library to add probes that allow tracing our code (although this task is better handled by more complex IDEs's and debuggers) but it is mostly used for application-level instrumentation.
Up to this point the concepts of binary instrumentation and the levels ore instrumentation have been introduced, however before going into details about how instrumentation tools are structured the next section describes what Frida is and the role it takes in the instrumentation process.
Frida: a binary instrumentation toolkit¶
Frida is a binary instrumentation toolkit developed by Ole Andre V. Ravnas and sponsored by NowSecure. There are other frameworks available to achieve similar things like Intel PIN and DynamoRIO but there are some key points that makes Frida an interesting toolkit over the others:
- Cross-platform: Frida works in Windows, Linux, MacOS systems as well as mobile platforms (Android, iOS).
- We can develop our instrumentation code in JavaScript or TypeScript, which speed things up a lot compared to other tools or frameworks.
- There are bindings available in various languages: Python, Java, Swift…
- Compared to other instrumentation frameworks such as PIN, development is easier and faster due to Frida's very straight-forward API as well as its setup process.
- Open-source: We can add features that we need or check out how Frida works internally.
These are the main ‘features’ that make this framework interesting to us. However, there are some more interesting features such as the possibility of working in other architectures like ARM or MIPS, and the fact that it is possible to make instrumentation software using the Frida libraries and/or toolkit and use it for commercial purposes.
This table helps illustrate the main advantages of Frida over other frameworks:
| Frida | DynamoRIO | PIN | |
|---|---|---|---|
| Open Source | Yes | Yes | No |
| Cross-Platform | Yes | Yes (limited) | Yes(limited) |
| Bindings in different languages | Yes | No | No |
| Write quick instrumentation tools | Yes | No | No |
| Support writing instrumentation without C | Yes | No | No |
| Mobile Support | Yes | No | No |
| Free | Yes | Yes | No |
The way Ole describes what is Frida is: “the Greasemonkey for native apps, a dynamic code instrumentation toolkit that lets you inject snippets of JavaScript or your own library into native apps on multiple systems”. For us it means that we can do all the flashy things that are possible to do with other instrumentation frameworks but faster due to the use of JavaScript to write instrumentation scripts and with high portability.
Regarding high portability, Frida supports the following Operating Systems and architectures:
Supported architectures and systems¶
Supported OS list and architectures:
- Windows (x86, x64)
- Linux (x86, x64, arm, arm64, arm64e)
- FreeBSD
- MacOS (x86, x64, Apple Silicon M1)
- Android (including x86)
- iOS (arm64, arm64e, x64)
Frida works with x86, x64 as well as ARM without problems and for other architectures like MIPS support can be added thanks to Frida being open-source or the use of prebuilt binaries by the community. There is also support for termux (an Android terminal emulator).
For a complete and up to date set of releases please refer to https://github.com/frida/frida/releases.
Now that Frida has been briefly introduced, in the next section we'll see how instrumentation tools are structured when using Frida and its role in them.
Instrumentation tool structure under Frida¶

The pattern described in Figure 1 is the one that should be followed when instrumenting an application unless certain conditions are met; some of them being the need to increase performance or decreasing complexity. In these cases, the instrumentation script and Frida's REPL should be good enough.
When writing an instrumentation tool there are two main parts to differentiate: The control script and the instrumentation script.
The control script is the one in charge of communicating with Frida via bindings. Bindings are libraries that offer access to the underlying Frida API from our language of choice. These are available in multiple languages: Python, Node, Swift, C#... In this book, when learning about writing the control script Python will be the language of choice (but you are always free to use others).
This script takes the role of loading the instrumentation script and injecting it into the target process. It also enables the child_gating feature which allows for child processes of a process that is being instrumented to be automatically instrumented too (reminder: this implementation is OS-dependant).
The control script also communicates with the instrumentation script and receives/sends all the messages from/to the instrumentation script and handles them as required (e.g: Handling events such as saving instrumentation messages or deactivating a function that is flooding our tool.)
Finally, it is also able to execute code from the instrumentation script via RPC(=remote procedure calls).
On the other hand, there's the instrumentation script which takes care of any interaction with the running process. This script is written in JavaScript and most of the book examples are written in JS(because it is what Frida's CLI welcomes and saves us time), however you are free to use TypeScript if you prefer. The instrumentation script has the ability of intercepting functions calls, monitoring process memory tracing instructions or function calls or even modifying the process execution flow. It is also able to send messages from the target process and is able to expose RPC methods to be called from Frida's REPL{#REPL}(a.k.a Frida's command line interface) or an external script.
Frida architecture basics¶
Let's picture an image of how Frida works internally with the help of some diagrams. But first, let's introduce the keywords of said diagram:
frida-coreis the part of Frida's internals that enables instrumentation with JS among other features (two-way communication, process enumeration...)frida-pythonare the bindings chosen to interact withfrida-core.frida-agentis a Frida library (fromfrida-core) that is injected into our target process and does the low-level stuff for us(installing hooks, communicating with our instrumentation code) and is written in JavaScript.frida-gumis a cross-platform instrumentation and introspection library (again, part offrida-core). For more details on what features it supports please refer to frida-gum's repository.
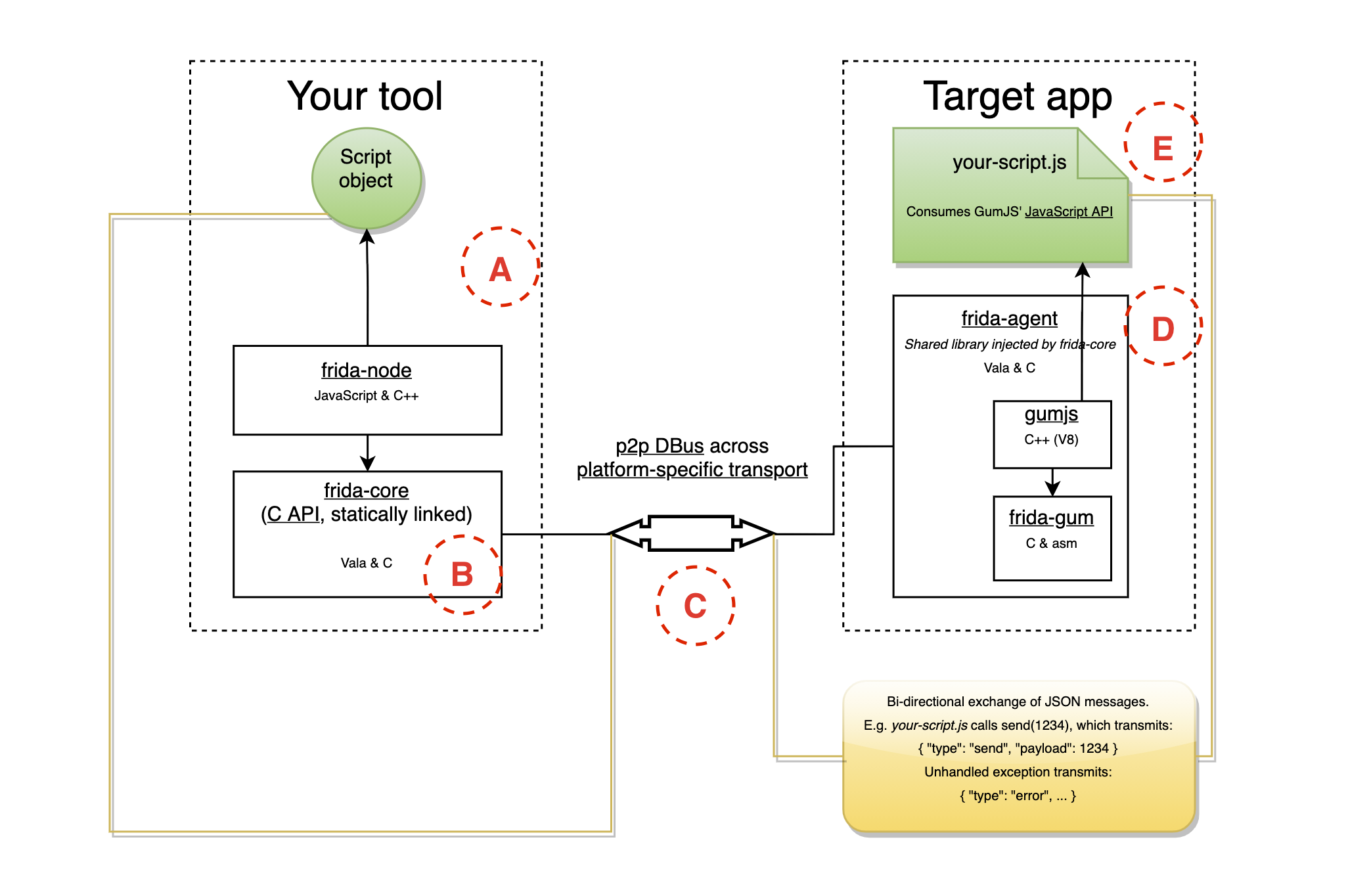
Taking Figure 2 as a reference, on the left labeled A there's the control tool that is written in Python (or it can be Frida's REPL) which communicates with frida-core labeled B through bindings (you can use C too, but that kind of defeats Frida's commodities).
On the right side, there is the frida-agent, labeled D, that is injected in the target process and interfaces with our JavaScript code labeled E via a P2P DBUS which transports a bidirectional exchange of JSON messages and is labeled C in Figure 2. If more control over instrumentation is required such as handling certain messages from JavaScript, processing child processes or calling functions from the agent RPC exports the control tool on the left side of Figure 2 is left to the user to be coded.
A more detailed explanation of Frida's architecture can be read at frida.re/docs/hacking.
After this brief introduction, if you are interested in some real-world projects powered by Frida you can take a look at the following list:
Projects using Frida
There are some interesting projects based on Frida, here I will be listing some of them however with a quick Google search you can see there are a lot more:
- Dwarf: A debugger using Frida as backend.
- APPMon: A tool to analyze MacOS and iOS applications, it instruments interesting APIs to inspect their usage or retrieving valuable information.
- r2frida: Extension that allows us to work with radare2 as well as Frida.
- frida-fuzzer: An experimental fuzzer for API in-memory fuzzing.
- Objection: A runtime mobile exploration toolkit based on Frida.
- It is also possible to find more projects thanks to the Frida topic in GitHub. https://github.com/topics/frida